EDI to Database
The EDI File Structure
Although an EDI file, and a database are similar in many ways, there really isn’t a one to one correlation between them even though a lot of people for the purpose of simplicity compare data elements of an EDI file to fields of a database, and a data segment of an EDI file to records of a database. This comparison may be acceptable to introduce people to EDI, but does not help when parsing and translating an EDI file into a database.
Data Element vs. Database Field
A data element is similar to a database field in that they both are containers of a data value. So in many instances one can map a data element to a database field simply
by their definition. For example, the BEG segment (in X12) has the following first three data elements defined as
"Transaction Set Purpose Code", "Purchase Order Type Code",
and "Purchase Order Number" respectively ...
BEG*00*SA*0101
...which can directly be mapped to fields in a record below:
Transaction Set Purpose Code Purchase Order Type Code Purchase Order Number 00 SA 0101
Data Segment vs. Database Field
However, in many instances,
it may be better to treat a data segment like a field, but would require some
"translation". For example, the DTM segment
DTM*002*20040723
To dump the data element values into fields correlated by their definitions as above would look like:
Date/Time Qualifier Date 002 20040723
But, if we translated the first data element value “002”, which is code for “Delivery Requested, then we can have a field that would make more sense:
Delivery Requested Date 07/23/2004
Data Segment Group or Loop vs. Database Record
Just like many fields would make up a record in a database, a group of data segments would also make up a record, and should be mapped into a record in a
database. Below is an example of a group of data segments that would make up a database record.
ST*850*00023
BEG*00*SA*0101
DTM*002*20040723
The above data segments can get translated into a database record shown below:
Message No Purchase Order No Delivery Requested Date 0023 0101 07/23/2004
Note that there are no hard and fast rules when translating data element values into a database. In the example above, elements that had a constant value were not mapped into the database record e.g. "850", "00", and "SA".
Loops vs. Database Table
So if a group of segments make
up a record, then each iteration of the same groups of segments (loop) would be
an additional record, and a set of records would be a table in a
database. For example, the groups of data segments in an EDI file
ST*850*00023
BEG*00*SA*0101
DTM*002*20040723
…
SE
…
ST*850*00024
BEG*00*SA*0102
DTM*002*20040723
…
SE
…
ST*850*00025
BEG*00*SA*0107
DTM*002*20040723
...would get mapped into the following database table
Header Table
Message No Purchase Order No Delivery Requested Date 0023 0101 07/23/2004 0024 0102 07/23/2004 0025 0107 07/23/2004
However, in many loop cases, each iteration of the loop can have a completely set of information from each other. For example, the N1 loop can have a "BillTo" information in one iteration, and a "ShipTo" information in the next one.
N1*BT*COMPANY ABC~
N3*123 DRIVE STREET~
N4*STARCITY*CA*76503~
N1*ST*INC XYZ~
N3*987 AVENUE ROAD~
N4*RANCH CITY*TX*30603~
These kinds of loops will normally have a data element called an entity identifier, which will contain a code to identify the loop information. In the N1 segment, the first data element is the entity identifier. In our example above, the entity identifiers have the value "BT", and "ST" to mean "BillTo" and "ShipTo" respectively. They can get mapped to the following database tables:
Bill To Table
PO No Company Name Address City State Zip 0101 COMPANY ABC 123 DRIVE STREET STARCITY CA 76503
Ship To Table
PO Company Name Address City State Zip 0101 INC XYZ 987 AVENUE ROAD RANCHCITY TX 30603
However since both tables have a one to one relationship with the Header table, it is be better to map them into the same Header table record, than having separate tables for each loop instances.
Header Table
Message No Purchase Order No Delivery Requested Date BillTo Company Name BillTo Address BillTo City BillTo State BillTo Zip ShipTo Company Name ShipTo Address ShipTo City ShipTo State ShipTo Zip 0023 0101 07/23/2004 COMPANY ABC 123 DRIVE STREET STARCITY CA 76503 INC XYZ 987 AVENUE ROAD RANCHCITY TX 30603
So if wad had an EDI file with the following content with 5 loops (including the Transaction Set/Message that starts with the ST segment, and ends with the SE segment)
ST*850*00023
BEG*00*SA*0101**20040723
DTM*002*20040723~
N1*BT*COMPANY ABC~
N3*123 DRIVE STREET~< N4*STARCITY*CA*76503~
N1*ST*INC XYZ~
N3*987 AVENUE ROAD~
N4*RANCH CITY*TX*30603~
PO1*1*16*EA*12.00**CB*000111111~
PO1*2*13*EA*30.00**CB*000555555~
…
SE*30*00023~
(If viewed with the eFileManager, the loops can be clearly defined).

We would have two tables: a Header table for Loop (or group) ST-SE, and Loops N1; and a Detail table for loops PO1.
Header Table
Message No Purchase Order No Delivery Requested Date BillTo Company Name BillTo Address BillTo City BillTo State BillTo Zip ShipTo Company Name ShipTo Address ShipTo City ShipTo State ShipTo Zip 0023 0101 07/23/2004 COMPANY ABC 123 DRIVE STREET STARCITY CA 76503 INC XYZ 987 AVENUE ROAD RANCHCITY TX 30603
Detail Table
PO Quantity Unit Price Product ID 0101 16 EA 12.00 000111111 0101 13 EA 30.00 000555555
Dumping an EDI file into a Database
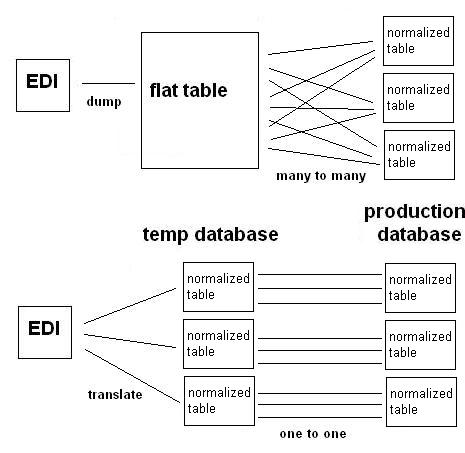
Many programmers especially those who are new to EDI have the erroneous idea that it is easier to “dump” data from an EDI file into a flat table so that they can later manipulate, organize and transfer the data into a relational database. They also incorrectly think that this method avoids them from having to know the EDI file structure. But, not only is this thinking wrong (since it takes just about the same amount of coding to dump data into a flat table, as it would to translate an EDI file directly into a normalized relational database); but it is also inefficient, which has a greater chance of creating errors because it creates two processes that would have to be executed in series before the data in the EDI file can finally be used.
The problem with dumping an EDI file into a database table without any translation of the qualifiers or entities is that the data would make little sense. For example, an EDI section with the following data
BEG*00*SA*0101**20040723~
N1*BT*COMPANY ABC~
N3*123 DRIVE STREET~
N4*STARCITY*CA*76503~
N1*ST*INC XYZ~
N3*987 AVENUE ROAD~
N4*RANCHCITY*TX*30603~
…with loop entities “BT” and “ST” for “Bill To” and “Ship To” respectively will look like below if dumped into a table with no translation.
PO No PO Date Qlfr Company Name Address City State Zip 0101 20040723 BT COMPANY ABC 123 DRIVE STREET STARCITY CA 76503 0101 20040723 ST INC XYZ 987 AVENUE ROAD RANCHCITY TX 30603
Therefore another process would have to get created and run, to translate the above database so that the data can finally report more useful information as shown below.
Purchase Order Information
PO No PO Date 0101 20040723
Bill To Information
PO No Company Name Address City State Zip 0101 COMPANY ABC 123 DRIVE STREET STARCITY CA 76503
Ship To Information
PO Company Name Address City State Zip 0101 INC XYZ 987 AVENUE ROAD RANCHCITY TX 30603
Another problem with dumping an EDI file into a flat table, is that the flat table becomes inefficiently huge with many redundant data. For example, using the same section of an EDI file ...
ST*850*00023~
BEG*00*SA*0101**20040723~
DTM*002*20040723~
N1*BT*COMPANY ABC~
N3*123 DRIVE STREET~
N4*STARCITY*CA*76503~
N1*ST*INC XYZ~
N3*987 AVENUE ROAD~
N4*RANCHCITY*TX*30603~
PO1*1*16*EA*12.00**CB*000111111~
PO1*2*13*EA*30.00**CB*000555555~
…
SE*30*00023~
...we would end up with a flat table as shown below.
Msg No PO NO PO DATE Qlfr Company Name Address City State Zip Qty Unit Price Product ID 00023 0101 20040723 BT COMPANY ABC 123 DRIVE STREET STARCITY CA 76503 16 EA 12.00 000111111 00023 0101 20040723 ST INC XYZ 987 AVENUE ROAD RANCHCITY TX 30603 16 EA 12.00 000111111 00023 0101 20040723 BT COMPANY ABC 123 DRIVE STREET STARCITY CA 76503 13 EA 30.00 000555555 00023 0101 20040723 ST INC XYZ 987 AVENUE ROAD RANCHCITY TX 30603 13 EA 30.00 000555555
The redundancy of data in the flat table can be clearly seen from this example with a small portion of an EDI file. Had there been more loops in the EDI file, the size of the table would have been exponentially bigger. The size as well as the redundancy of data in the flat table would make managing and translating the information over into an existing production database difficult.
On the other hand, if the EDI file were to be translated directly into a normalized relational database, the transfer of data over to the production database would be a one-to-one correlation between the fields of the two databases.
Figure 1. Illustrates the relationship between the intermediate database and the production database. It is better to translate the parsed data from an EDI file into normalized tables so that it would be easier to port over the data to your production database.
Click here to download example programs.
Click here to evaluate the Framework EDI

The example programs provided in this article are for illustration only, and have no purpose other than to show software developers how to use the Framework EDI component in programming languages to process EDI files. If you have any questions, don't hesitate to contact us:
